One of the first things I learned in R was how to use basic statistics functions like sum(). However, what if you want a cumulative sum to measure how something is building over time–rather than just a total sum to measure the end result? It turns out there is a function for cumulative sum, called cumsum(). Here’s out to use it…
### create (or import) a data frame of totals
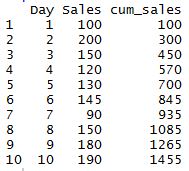
product_sales <- data.frame("Day" = c(1:10),"Sales" = c(100,200,150,120,130,145,90,150,180,190))
### add cumulative column to the data frame
product_sales[,"cum_sales"] <- cumsum(product_sales$Sales)
### print data frame
product_sales
It’s that simple. Here’s how the output looks from the dummy data frame I created: